Evolutionary Agent Societies
Steve G. Romaniuk
ANSER
Fairmont, WV 26554, USA
Email: romanius@anser.org
http://nexos.anser.org:8080/java/app/
ABSTRACT
Evolutionary Agent Societies (EAS) expand current agent-based IT solutions, by further emphasizing reliability, scalability, and adaptability of intelligent software. Reliability is addressed by seeking societies of similar agents, capable of cooperating and intelligently dividing complex tasks into manageable units. Autonomous, mobile agents capable of seeking each other out, based on their inherent problem solving qualities, and adept at forming loose societies, are sought. Scalability is addressed by both providing mobile agents and having masses of agents collaborate with one another in a parallel distributed manner. Adaptability is addressed by supplying individual agents with the capability to reproduce. Encoding agent capabilities in the form of agent persona's (defining an agent's capabilities, problem solving strategies, and biases), and allowing for natural selection among individual agents within a society, aims to harness the adaptability long observed and sought after in biological systems. This paper reports ongoing R&D efforts in exploiting EAS under the larger goal of constructing Autonomously Learning Intelligent Agents (ALIA) at ANSER. Tackling the tasks of automatic Facial Recognition from various video sources and exploitation of intranet/internet located data sources, is at the heart of this effort.
Keywords: Evolutionary Agent Societies, Learning, Autonomous, Knowledge Discovery, Data Mining.
1. INTRODUCTION
Locating missing and exploited children, a troubling problem of modern society, suffers from inadequate manpower support. Modern computer technology can substantially enhance the ongoing investigative efforts and has obvious spin-off potential for law enforcement in general. ANSER, under a grant by the National Institute for Justice (NIJ), is closely working with the National Center for Missing and Exploited Children (NCMEC) in developing advanced technology for integrating automated facial recognition software and automated analysis of case-related information via expert systems and data mining tools. This paper focuses on the later of these two tasks.
2. EVOLUTIONARY AGENT SOCIETIES
Evolutionary Agent Societies (EAS) encompass software systems, in which individual processes exhibit agent-like behavior [2,8] (i.e., communication, mobility, etc.) and agents are capable of forming social structures (i.e., cooperate, form relations of differing intensities and frequencies, etc.). Individual agents are endowed with personas, which define the agent's basic behavioral and problem solving skills. Evolutionary principles are employed to evolve individual populations of agents, and it is anticipated that a rich pool of agent behavioral traits and capabilities will give rise to the emergence of agent societies.
3. EAS APPLIED TO DATA MINING
Current efforts in data mining systems work best on known information sources. In other words, they rely on human managers to turn unstructured or semi-structured information sources into agent sources. Typical approaches utilize ontologies to provide a common interface for knowledge representation and discovery [7,14]. There is nothing wrong with this approach, as long as one seeks to agentify information from known and analyzed data sources; and there is enough manpower and time for creating the required ontologies. ANSER's approach to data mining seeks fully autonomous agents capable of discovering data sources and their inherent relations. This approach is necessitated by the distribution of a large number of potential data sources (i.e., Individual State Clearinghouses for Missing and Exploited Children, National Directory of New Hires, DMV, etc.). The following architecture will serve as a brief example of how EAS can be used to accomplish these goals.
4. OVERVIEW OF EAS-DM SYSTEM
The EAS Data Mining system (EAS-DM) consists of several different types of agents (to be discussed in more detail latter on). Two types of agent populations are embedded in the current configuration:
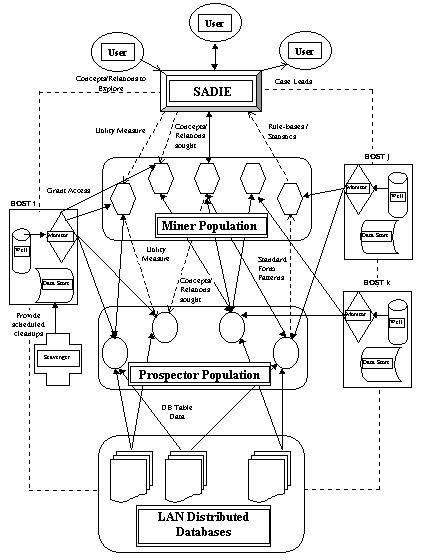
Figure 1. EAS-DM Architecture
Figure 1. outlines a high-level description of the overall system architecture. The general flow of information/data is as follows:
Initially, an autonomous population of Prospector agents is engaged in data mining of existent ODBC-compliant databases (these databases have either been identified by humans or via a Surveyor agent). The knowledge discovery strategies exploited by the Prospector agents will be discussed a little latter in this paper. Similar to conventional data mining tools, the Prospector agents attempt to find interesting relationships between groups of database table fields (both intra- and inter-table relations) and format these in a standard symbolic data definition format. An example of such a Prospector agent generated data file is detailed in Figure 2. This particular example shows 4 independent and 1 dependent feature variable. Part of the transformation of database tables into data definition files, requires mapping about 2 dozen ODBC data types into 3 basic data types. These are:
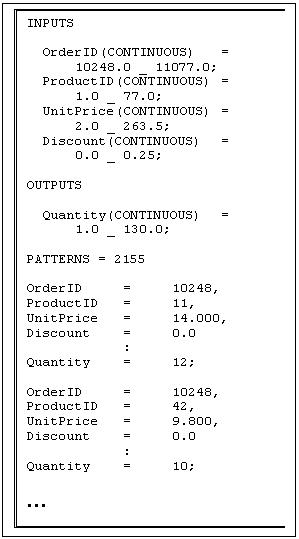
Figure 2. Sample Data Definition file generated by Prospector Agent
The first two data types are primarily used for symbolic data, whereas the latter is invoked to represent numeric data. Prospector agents invoke various strategies (as dictated by their internal biases) when transforming database tables into data definition files. These strategies can be either classified as (a) table expanding, or (b) table contracting (expansion/contraction simply refers to the increase/decrease in table fields).
Prospector Agents and Discovery Strategies
Table Expansions: A typical table expanding transformation is field decomposition. The enabling strategy behind this transformation seeks out table fields, which within some agent specific thresholds contain common sub-field delimiters. Once such sub-fields have been identified, the original table field is decomposed into as many sub-fields. For example, table fields, which contain social security numbers, would be decomposed into 3 sub-fields. Other common examples of fields which can be readily decomposed are: telephone numbers, addresses, identification numbers (i.e., serial numbers, bar and other codes), composite measurements (i.e., feet/inches, kilo/grams, etc.), dates (when stored as numeric or text fields), and many others. As mentioned before, individual Prospector agents employ their own biases when deciding whether a field can be decomposed, and into how many sub-fields. This operation is driven by threshold parameters (a certain number of table records have to display a common set of potential sub-fields). For example, if the threshold value is set high, a proportionally small number of sub-fields will be identified and created, as opposed to a low threshold value resulting in a large number of potential sub-fields.
Table Contractions: This transformation attempts to reduce the number of potential fields in a table. Table contractions can occur in a number of ways. The two more popular approaches are field deletions and field merging. The former relies (similar to field decomposition) on threshold parameters to decide whether a table field has potential to act as either a dependent or independent variable. As a demonstrative example, consider the following scenario: assume that a table field consists of a large collection of unique symbolic values. Such a field would have little value to act as a feature predictor and even less value in being used as a predicted feature. A similar situation arises when a field contains only unique numeric values. A field of this makeup could be, for example, a counter, product id, etc, which is also best deleted. Finally, field merging, refers to operations commonly known as principal components analysis. In this particular case, a group of table fields may be merged into a single field via some linear combination of the original group fields. The data mining and pattern recognition literature contains several references to this type of table contraction operation [1,3,13].
Data Mining Agents and Prediction
Data-mining agents on the other hand can subscribe and receive data definition files, which are generated by the Prospector agents. The first step that is performed by a Mining agent, is to convert the generic data definition file into a specific pattern file suitable for supervised learning from examples. The Mining agent employed in the EAS-DM system is based on an incremental Instance-Based Learning (IBL) algorithm. The system learns by automatically forming instance neighborhoods in the form of n-dimensional hyper-boxes. See [10] for a detailed discussion of this type of IBL system. The IBL system used in this work is augmented to support extraction and refinement of symbolic rules and is characterized by a fast - provably deterministic - learning approach (important to the data-mining task undertaken in this project). Figure 3 lists an example pattern file generated by the Data Mining agents. Notice that the original data is directly encoded into numeric data. Depending on the type of pattern recognition algorithm employed by the Data Mining agents, it may be necessary to encode non-numeric features. Encoding of features is based on an agent's internal biases and can support independent feature and dependent feature coding. As an example of the former, consider direct binary coding in which every feature value is encoded as a separate bit. Dependent feature coding can utilize any number of binary codes (i.e., gray codes, standard binary, BCD, etc.). As is the case with the Prospector agent, a number of different strategies (i.e., biases) are available for coding symbolic features. The decision, of which feature coding strategy, distance measure (required for building instance neighborhoods), table field contraction/expansion methods, etc. to use, is encoded in each agents chromosome.
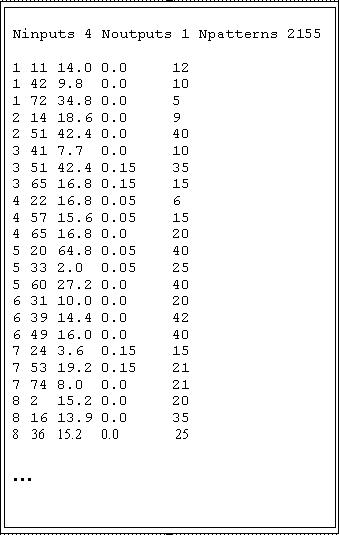
Figure 3. Data mining specific pattern file
The final output of the Mining agent is a file of rules deemed relevant by the agent. These rules are forwarded to SADIE agents for further use. Figure 4 contains such a sample. Note that the rules are represented in Lisp notation, the language in which SADIE is currently implemented (A Java interface is in the works.). SADIE uses the agent generated rules to complement and enhance its own decision making and planning operations (SADIE's core knowledge base is created by interviewing NCMECs case workers and adding their domain expertise), when deciding on prioritizing case leads.
This completes the description of the upward flow of the information food chain of the EAS-DM system (i.e., DBs -> Prospector -> Data Miner -> SADIE - > Users).

Figure 4. Sample SADIE rules generated by Mining agents
In order to apply breeding to the agent populations, it is imperative to provide feedback to individual agents, so as to decide on overall fitness measures. This feedback process of one or more performance utility measures is referred to as the downward flow of information. As detailed in Figure 1., feedback information can come in two flavors:
SADIE provides a utility measure for individual rules or rules groups (if used in same context) on the basis of their usefulness in creating new case leads.
In this mode, SADIE instructs individual Mining agents to generate rules for specific concepts and their relation to other concepts. For example, through the use of a Thesaurus, or feedback from actual case-workers, SADIE can be informed of concepts that are related, but for which no explicit rule knowledge exists.
Both direct and indirect feedback is propagated from the Mining agent population to the Prospector agent community. Based on the performance of each of the agents and their interests (in seeking out specific knowledge based on their internal biases), Mining and Prospector agents enter relationships of cooperation/ avoidance/ friendship as deemed fit. It is anticipated that with enough diversity in the agent populations and long term sustainability of the EAS-DM system, structures similar to biologically inspired societies emerge.
Similar to either SADIE or individual users providing direct feedback to the Mining agents, users can also provide feedback in the form of hints to the Prospector population. Hints contain suggestions with regard to:
As the name indicates, Hints are only suggestions and individual agents (based on their persona) may decide to reject them altogether, whereas other agents may follow them religiously.
To complete the descriptions of the EAS-DM system in Figure 1., consider the boxes labeled HOST x (x = i, j, k). Host simply refers to a network computer running a Monitor agent. Monitors perform basic load balancing by either granting/ denying/ suspending/ resuming other agent's access to the host system they reside on. The Well is an agent generating source, which is used to bootstrap and possibly replenish agent populations for a given computer network. Agents running on any particular host, take advantage of local data storage mediums for their processing purposes. Scavenger agents are responsible for cleaning up the local store of residual data files.
Types of Agents
The ANSER Data Mining EAS defines 6 different agents. Each is briefly discussed with respect to their behavioral patterns.
Surveyor Agent: an agent capable of traversing intranets and the internet. Its purpose is to identify structured (i.e., databases, knowledge bases, XML-enabled pages) and unstructured data sources (i.e., text documents, HTML pages, etc.). Relevant resources uncovered by the Surveyor are forwarded to the Prospector for further processing.
Prospector Agent: can come in different flavors depending on the task it is assigned to. This agent is invoked by Surveyor agents and pointed towards promising data sources. The agents' task is to perform knowledge discovery and pre-format the encountered data so it can be further processed by Mining agents.
Mining Agent: receives its data from different Prospector agents. Its goal is to identify possibly interesting relations contained in the data and output them in a human or machine-readable format (i.e., rules for expert system shells). Mining agents can also come in different flavors, exploiting various biases in multi-strategy learning (MSL) approaches.
SADIE Agents: a cyclic, hierarchical, adversial planning system that allows these agents to constantly interact with their environment; new problems are constantly arising, each requiring new or revised plans. These agents have knowledge bases of concepts, goals, and events and a rule base that may perform both crisp and fuzzy inferences. SADIE agents incorporate expert-derived knowledge collected from NCMEC case-workers with knowledge discovered by the Mining Agents. The latter allows for automated knowledge refinement. By utilizing SADIE's introspection capabilities, it is possible to feedback information on the agent-supplied knowledge (i.e., how useful it was in solving a planning subtask). Feedback can occur in one of two ways: (a) implicit, provide a usability measure of the received knowledge, (b) explicit, ask data mining agents to provide knowledge about certain concepts that SADIE requires for its task planning operations.
Monitor Agent: responsible for monitoring system resources and granting access to a network host's resources to other EAS agents. This agent is also responsible for launching other agents on the current host and suspending/aborting agents (i.e., perform dynamic load balancing).
Scavenger Agent: cleans up intermittently generated data files/cookies etc., which where not properly removed during the generating agents existence. It is quite conceivable that individual agents will end their existence prematurely and consequently leave behind resource wasting files.
5. EVOLUTION AND AGENT PERSONAS
Agent Persona
An agent's persona defines an agent's general and specific capabilities. Personas are inherited from an agent's parents and modified during an agent's existence through its personal experiences. They embody all pertinent behavioral characteristics the agent will display during its lifetime. All EAS-DM agents have their own unique personas, which sometimes overlap. Some examples of inherited persona traits are:
Traits, which are adapted during the existence of an agent, include:
Naturally, traits listed as being inherited may also subsequently be modified based on environmental conditions. For example, reproduction is largely inherited, but its frequency can change dependent on other agent persona traits (agents ability to attract other agents for procreation), or that of the whole society (society conscious agents may defer reproduction due to resource shortages).
Individual traits can be either encoded as single genes or gene-groups. For example, degree of cooperation consists of genes indicating the degree of inter- and intra-agent cooperation (i.e., Prospector/Prospector, or Miner/Prospector). Since a large proportion of traits is represented by continuous values, bounds are placed on these values. Gene bounds are inherited and can not be changed during an agent's existence. On the other hand, actual trait values can be modified dynamically (move within a gene's specified bounds).
Evolution
As mentioned in the previous section, persona traits are encoded as individual genes or gene groups. Since genes are composed of real values, continuous parameter genetic algorithms are utilized during agent reproduction. Value extrapolating gene blending (within the inherited parental value bounds) is invoked to create offspring. Crossover operators considered are either simple, weighted, or blocked. For a more detailed discussion on the latter two, the interested reader is referred to [9].
Agents procreate on the basis of their explicit and implicit fitness functions. Explicit fitness is essentially a combined utility measure, propagated to the agent (producer of a service) from one or more of its services consumers. This fitness measure propagates down the agent hierarchy (i.e., from SADIE -> Miner -> Prospector -> Surveyor). Implicit fitness is agent-type specific and is dependent on the agents core services. For example, the Prospector agent creates data definition files, whereas the Miner agent generates rule-bases. Since the learning algorithm employed by the Miner agent is based on instances and a measure of the quality of this algorithm is instance reduction, this very measure qualifies as an implicit fitness measure. Naturally, other agent-task specific measures can qualify as implicit fitness measures.
Population overload is addressed in three ways: Firstly, host Monitor agents restrict the number of agents that can enter a network. Whether agents enter the network because the agent Well creates them, or by means of reproduction, in either case only the number of agents supported by individual hosts are accommodated. Secondly, the reproduction/procreation gene-group limits the number of new agent births, if the network is taxed beyond its limitations (lack of resources reduces sex drive and consequently the generation of offspring). Thirdly, agent longevity bounds guarantee that agents will die in due time, regardless of their capabilities and perceived usefulness (Even the best of them have to eventually go...).
6. IMPLEMENTATION
The EAS-DM system is with the exception of SADIE, written entirely in Java. At the time of writing, the Prospector, Miner and Monitor agents have been implemented in part. Even though the upward propagating information food chain is implemented, the Prospector agent only supports intra-table discovery. Inter-table and inter-database discovery is planned for the near future. To address learning of unstructured database fields (i.e., larger text fields such as memos) machine learning for text categorization [4] is currently being implemented.
7. RELATED WORK
The EAS-DM system expands on earlier work by the author on utilizing EAS for automating the predictive data mining process [11]. A prototypical system for the Windows 95 & NT platform was constructed around a population of TDL [12] (Trans-Dimensional Learning) agents. These agents are capable of learning, cooperating, and reproducing. Furthermore, TDL agents are adept at learning pattern associations across databases. In other words, data pattern sources of different dimensional specifications can be learned and represented within a single homogenous neural network. Finally, the various network structures, which have been learned by individual TDL agents can be fused by Collector agents into a single network.
The Amalthaea system [6] is an example of an evolving, multi-agent ecosystem for personalized filtering, discovering, and monitoring of information sites. Amalthaea's ecosystem provides an environment endowed with limited resources and supports evolving and cooperative agents. This particular architecture is based on two types of agents: (a) Information Filtering and (2) Information Discovery. Filtering agents keep track of user interests, whereas discovery agents handle actual information resources including adapting to them. A very different system (at least in terms of its application) is Creatures [5], a commercial home-entertainment software package. Creatures' provides a simulated environment, which is inhabited by synthetic agents (virtual pets) that the user can interact with. Individual creatures implement an artificial biochemistry for modeling energy metabolisms. Variable length genetic codes implement the pets' biochemistry and allow for evolutionary adaptation.
InfoSleuth [7,14] is both an architecture and toolkit for deploying agent systems, with the focus of operation being information gathering and analysis over dynamic networks and multimedia information sources. This system does not support evolutionary principles.
8. CONCLUSIONS
The above described EAS system is minimalist in describing an information food chain. Knowledge percolates from the data sources (structured and unstructured) all the way up to the final consumer - SADIE. Societies of agents can work on the supplied data, each equipped with different biases of how these data sources should be transformed /mined/utilized. Agents with similar biases can learn to cooperate and solve a task in parallel. Mining agents' biases can be modified (i.e., adapted), by remembering past problem solving operations and solutions. By equipping individual agents with Persona's (agent characteristics) and employing evolutionary principles to agents' pro-creation, it is possible to create cyber-diversity akin to the bio-diversity found in nature.
9. REFERENCES
[1] Bigus, J.P. (1996) Data Mining with Neural Networks, McGraw Hill Press.
[2] Bradshaw, M.J., (1997) Software Agents, MIT Press.
[3] Fayyad, U.M., Piatetsky-Shapiro, G., Smyth, P., Uthurusamy, R. (1996) Advances in Knowledge Discovery and Data Mining, MIT Press.
[4] Goldberg, Jeffrey L. (1996) CDM: An Approach to Learning in Text Categorization, International Journal on Artificial Intelligence Tools, Vol. 5, Nos. 1 & 2, pp. 229-253.
[5] Grand, S., Cliff, D., Malhotra, A. (1997) Creatures: Artificial Life Autonomous Software Agents for Home Entertainment, in Agents'97 Conference Proceedings.
[6] Moukas, A., Zacharia, G. (1997) Evolving a Multi-agent Information Filtering Solution in Amalthaea, in Agents'97 Conference Proceedings.
[7] Nodine, M. Perry, B., Unruh, A. (1998) Experience with the InfoSleuth Agent Architecture,
In Proceedings of AAAI-98 Workshop on Software Tools for Developing Agents, 1998.
[8] Nwana, H. S., Azarmi, N. (1997) Software Agents and Soft Computing: Towards Enhancing Machine Intelligence, Springer Publishing.
[9] Romaniuk, S.G. (1996) Learning to Learn with Evolutionary Growth Perceptrons, in Genetic Algorithms for Pattern Recognition, Pal, S.K. and Wang, P.P., Eds., CRC Press, Inc.
[10] Romaniuk, S.G. (1994) Efficient Storage of Instances: The MultiPass Approach, in Procee. 7th Inter. Conf. On Industrial and Engineering Applications of Artificial Intelligence and Expert Systems, Austin, Texas, June, 1994.
[11] Romaniuk, S.G. (1995) TDL Agents applied to Autonomous Data Mining, White Paper: Universal Problem Solvers, Inc. (Also see Through the Looking Glass... in TDL's Windows Help System, http://pages.prodigy.com/upso).
[12] Romaniuk, S.G. (1993) Trans-Dimensional Learning, International Journal of Neural Systems, Vol. 4, No. 2, pp. 171-185.
[13] Weiss, S. M., Indurkhya, N. (1998) Predictive Data Mining, Morgan Kaufmann Publishers, Inc.
[14] Woelk, D., Tomlinson, C. (1994) The InfoSleuth Project: Intelligent Search Management via Semantic Agents, Second International World Wide Web Conference, October, 1994.