Figure 1
We would all like to have a good theory of perception. Such a theory would account for all the known phenomena and predict novel phenomena, explaining everything in terms of processes occurring in nervous systems in accordance with the principles and laws already established by science: the principles of optics, physics, biochemistry, and the like. Such a theory might come to exist without our ever having to answer the awkward "philosophical" question that arises:
What exactly is the product of a perceptual process?
There seems to be an innocuous--indeed trivial--answer:
The product of a perceptual process is a perception!
What could be more obvious? Some processes have products, and the products of perceptual processes are perceptions. But on reflection, is it so obvious? Do we have any idea what we might mean by this? What are perceptions? What manner of thing--state, event, entity, process--is a perception? It is merely a state of the brain, we may say (hastening to keep dualism at bay), but what could make a state of the brain a perceptual state as opposed to, say, merely a metabolic state, or--more to the point --a pre-perceptual state, or a post-perceptual state? For instance, the state of one's retinas at any moment is surely a state of the nervous system, but intuitively it is not a perception. It is something more like the raw material from which subsequent processes will eventually fashion a perception. And the state of one's motor cortex, as it triggers or controls the pressing of the YES button during a perceptual experiment is intuitively on the other side of the mysterious region, an effect of a perception, not a perception itself. Even the most doctrinaire behaviorist would be reluctant to identify the button-pressing behavior of your finger as itself the perception; it is a response to . . . what? To a stimulus occurring on the retina, says the behaviorist. But now that behaviorism is history we are prepared to insist that this peripheral response is mediated by another, internal response: a perception is a response to a stimulus and a behavioral reaction such as a button-press is a response to a perception. Or so it is natural to think.
Natural or not, such ways of thinking lead to riddles. For instance, in a so-called computer vision system does any internal state count as a perception? If so, what about a simpler device? Is a geiger counter a perceiver--any sort of perceiver? Or, closer to home, is thermoregulation or electrolyte balance in our bodies accomplished by a perceptual process, or does such manifestly unconscious monitoring not count? If not, why not? What about "recognition" by the immune system? Should we reserve the term "perception" for processes with conscious products (whatever they might be), or is it a better idea to countenance not only unconscious perceptual processes, but also processes with unconscious perceptions as their products?
I said at the outset that a good theory of perception might come into existence without our ever having to get clear about these awkward questions. We might achieve a theory of perception that answered all our detailed questions without ever tackling the big one: What is a perception? Such a state of affairs might confound the bystanders--or amuse or outrage them, but so what? Most biologists can get on with their work without getting absolutely straight about what life is, most physicists comfortably excuse themselves from the ticklish task of saying exactly what matter is. Why should perception theorists be embarrassed not to have achieved consensus on just what perception is?
"Who cares?" some may say. "Let the philosophers haggle over these stumpers, while we scientists get on with actually developing and testing theories of perception." I usually have some sympathy for this dismissive attitude, but I think that in this instance, it is a mistake. It leads to distortion and misperception of the very theories under development. A florid case of what I have in mind was recently given expression by Jerry Fodor (in a talk at MIT, November 19, 1991):
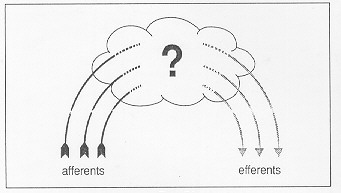
Cognitive Science is the art of pushing the soul into a smaller and smaller part of the playing field.If this is how you think--even if this is only how you think in the back of your mind--you are bound to keep forcing all the phenomena you study into the two varieties: pre-perceptual and post-perceptual, forever postponing a direct confrontation with the product at the presumed watershed, the perception or perceptual state itself. Whatever occupies this mysterious middle realm then becomes more and more unfathomable. Fodor, on the same occasion, went on to say in fact that there were two main mysteries in cognitive science: consciousness and the frame problem--and neither was soluble in his opinion. No wonder he thinks this, considering his vision of how Cognitive Science should proceed. This sort of reasoning leads to viewing the curving chain of causation that leads from pre-perceptual causes to post-perceptual effects as having not only a maximum, but a pointed summit--with a sharp discontinuity just where the corner is turned. (As Marcel Kinsbourne has put it, people tend to imagine there's a gothic arch hidden in the mist.)
Figure 1
There is no question that the corner must be turned somehow. That's what perception is: responding to something "given" by taking it--by responding to it in one interpretive manner or another. On the traditional view, all the taking is deferred until the raw given, the raw materials of stimulation, have been processed in various ways. Once each bit is "finished" it can enter consciousness and be appreciated for the first time. As C. S. Sherrington (1934) put it:
The mental action lies buried in the brain, and in that part most deeply recessed from outside world that is furthest from input and output.I call the mythical place somewhere in the center of the brain "where it all comes together" for consciousness the Cartesian Theater (Dennett, 1991, Dennett and Kinsbourne, 1992). All the work that has been dimly imagined to be done in the Cartesian Theater has to be done somewhere, and no doubt all the corner turning happens in the brain. In the model that Kinsbourne and I recommend, the Multiple Drafts Model, this single unified taking is broken up in cerebral space and real time. We suggest that the judgmental tasks are fragmented into many distributed moments of micro-taking (Kinsbourne, 1988). There is actually very little controversy about the claim that there is no place in the brain where it all comes together. What people have a hard time recognizing--and we have a hard time describing--are the implications of this for other aspects of the traditional way of thinking.
I want to concentrate here on just one aspect: the nature of "takings". An accompanying theme of Cartesian materialism, what with its sharp discontinuity at the summit, is the almost irresistible tendency to see a sharp distinction between, on the one hand, the items that presumably reside at the top, and, on the other hand, the various items that are their causes and effects. The basic idea is that until some content swims all the way up from the ears and retinas into this Theater, it is still just pre-conscious, pre-experienced. It has no moxie; it lacks the je ne sais quoi of conscious experience. And then, as the content completes its centripetal journey, it abruptly changes status, bursting into consciousness. Thereafter, the effects that flow, directly or indirectly, from the Audience Appreciation that mythically occurs in the Cartesian Theater count as post-conscious, and these effects, too, lack some special something.
Let's consider a garden variety case of this theme in slow motion, working backwards from peripheral behavior to conscious perception. Suppose you tell me you believe in flying saucers. Let us further suppose that that behavior--the telling--is an indirect effect of your once having been shown a highly detailed and realistic photograph of what purported to be a flying saucer. The behavior of telling is itself an indirect effect of your belief that there are flying saucers--you are telling me what you actually believe. And that belief in turn is an effect of yet another prior belief: your belief that you were shown the photograph. And this belief that you were shown the photograph was originally supported by yet prior beliefs of yours about all the details in the photograph you were shown. Those beliefs about the particular details of the photograph and the immediate perceptual environment of your looking at it were themselves short-lived effects--effects of having seen the photograph. They may all have faded away into oblivion, but these beliefs had their onset in your memory at the very moment--or very shortly thereafter--that you had the conscious visual perception of the photograph. You believe you saw the photograph because you did see the photograph; it didn't just irradiate your retinas; you saw it, consciously, in a conscious experience.
It looks as if these perceptual beliefs are the most immediate effect of the perceptual state itself Endnote 1. But they are not (it seems) the perception itself, because they are (it seems) propositional, not . . . um, perceptual. That at least is a common understanding of these terms. Propositional, or conceptual, representations are more abstract (in some hard-to-define way), and less, well, vivid and colorful. For instance, V. S. Ramachandran draws our attention to the way the brain seems to "fill in" the region of our blind spots in each eye, and contrasts our sense of what is in our blind spot with our sense of what objects are behind our heads:
For such objects, the brain creates what might be loosely called a logical inference. The distinction is not just semantic. Perceptual and conceptual representations are probably generated in separate regions of the brain and may be processed in very different ways.(Ramachandran, 1992, p.87)Just what contrast is there between perceptual and conceptual? Is it a difference in degree or kind, and is there a sharp discontinuity in the normal progression of perceptual processes? If there is, then one--and only one--of the following is the right thing to say. Which is it to be?
(1) Seeing is believing. My belief that I see such and such details in the photograph in my hand is a perceptual state, not an inferential state. I do, after all, see those details to be there. A visually induced belief to the effect that all those details are there just is the perception!
(2) Seeing causes (or grounds) believing. My belief that I see such and such details in the photograph in my hand is an inferential, non-perceptual state. It is, after all, merely a belief--a state that must be inferred from a perceptual state of actually seeing those details.Neither, I will argue, is the right thing to say. To see why, we should consider a slightly different question, which Ramachandran goes on to ask: "How rich is the perceptual representation corresponding to the blind spot?" Answers to that eminently investigatable question are simply neutral with regard to the presumed controversy between (1) and (2). One of the reasons people tend to see a contrast between (1) and (2) is that they tend to think of perceptual states as somehow much richer in content than mere belief states. (After all, perceptions are like pictures, beliefs are like sentences, and a picture's worth a thousand words.) But these are spurious connotations. There is no upper bound on the richness of content of a proposition. So it would be a confusion--a simple but ubiquitous confusion--to suppose that since a perceptual state has such-and-such richness, it cannot be a propositional state, but must be a perceptual state (whatever that might be) instead.
No sane participant in the debates would claim that the product of perception was either literally a picture in the head or literally a sentence in the head. Both ways of talking are reckoned as metaphors, with strengths and shortcomings. Speaking, as Kinsbourne and I have done, of the Multiple Drafts Model of consciousness leans in the direction of the sentence metaphor, in the direction of a language of thought. (After all, those drafts must all be written, mustn't they?) But our model could just as readily be cast in picture talk. In Hollywood, directors, producers and stars fight fiercely over who has "final cut"--over who gets to authorize the canonical version of the film that will eventually be released to the public. According to the Multiple Cuts Model, then, nobody at Psychomount Studios has final cut; films are made, cut, edited, recut, re-edited, released, shelved indefinitely, destroyed, spliced together, run backwards and forwards--and no privileged subset of these processes counts as the Official Private Screening, relative to which any subsequent revisions count as unauthorized adulterations. Different versions exist within the corridors and cutting rooms of Psychomount Studios at different times and places, and no one of them counts as the definitive work.
In some regards the Multiple Cuts version is a more telling metaphor--especially as an antidote to the Cartesian Theater. There are even some useful elaborations. Imagine cutting a film into its individual frames, and then jumbling them all up--losing track of the "correct" order of the frames. Now consider the task of "putting them back in order." Numbering the frames in sequence would accomplish this, provided that any process that needs access to sequencing information can then extract that information by comparing frame numbers. There is no logical necessity actually to splice the frames in order, or line them up in spatial order on the film library shelf. And there is certainly no need to "run" them through some projector in the chosen temporal order. The chosen order can be unequivocally secured by the numbering all by itself. The counterpart in our model of consciousness is that it does not follow from the fact that we are equipped to make sequence judgments about events in our experience that there is any occurrence in real time of a sequence of neural representations of the events in the order judged. Sometimes there may be such a sequence occurring in the brain, but this cannot be determined simply by an analysis of the subjective content of experience; it is neither a necessary nor sufficient condition for a like-ordered subjective sequence.
In other regards, however, the Multiple Cuts version of our model is altogether too vivid, what with its suggestions of elaborate pictorial renderings. We should be leery of metaphor, but is there any alternative at this point? Are there any non-metaphorical ways of talking that capture the points that need making? How about the terms being popularized by the connectionists: "vector coding and vector completion"? This new way of talking about content in cognitive science is appealing partly because whatever it is, vector coding is obviously neither pictures nor words, and partly, I suspect, because none of the uninitiated dare to ask just what it means!
Let me tell you what it means, so far as I can tell. Think of an enormous multi-dimensional hyperspace of possible contents--all the possible contents a particular organism can discriminate. A vector, if I may indulge yet again in metaphor, can be considered a path leading into a particular quadrant or subspace in this hyperspace. Vector completion is just the process of pursuing a trajectory to an ultimate destination in that hyperspace. Most of the hyperspace is empty, unoccupied. When something (some sort of thing) has been encountered by an organism, it renders the relevant portion of the organism's hyperspace occupied; recognizing it again (or being reminded of it by another, similar one) is getting back to the same place, the same coordinates, by the same or a similar path. Vector completion creates a path to a location in content-hyperspace.
"Vector completion" talk is just as metaphorical as "language of thought" talk or "pictures in the head" talk; it is simply a more abstract metaphorical way of talking about content, a metaphor which neatly evades the talk of pictures versus sentences, while securing the essential informational point: to "discriminate" or "recognize" or "judge" or "turn the corner" is simply to determine some determinable aspect of content within a space of possibilities.
Vector-completion talk is thus like possible world semantics; it is propositional without being sentential (see, e.g., Stalnaker, 1984). It provides a way of asserting that a particular "world" or "set of worlds" has been singled out from all the possible worlds the organism might single out for one purpose or another. Acknowledging that perception or discrimination is a matter of vector completion is thus acknowledging something so uncontroversial as to be almost tautological. Vector completion is a cognitive process in the same way growing old is a biological process; short of dying, whatever you do counts.
Almost tautological, but not quite. What the connectionists argue is that as long as you have machinery that can traverse this huge state-space efficiently and appropriately (completing the vectors it ought to complete most of the time), you don't have to burden the system with extra machinery--scene painting machinery or script-writing machinery. A highly particular content can be embodied in the state of a nervous system without having any such further properties--just so long as the right sort of transitions are supported by the machinery. Given the neutrality of vector-coding talk, there is no particular reason for the machinery described to be connectionist machinery. You could describe the most sentential and logistic of representation-systems in vector-coding terms if you wished. What you would lose would be the details of symbol-manipulation, lemma-proving, rule-consulting that carried the system down the path to completion--but if those features were deemed beneath the level of the intended model, so much the better. But--and here is the meat, at last--connectionist systems are particularly well-suited to a vector-coding description because of the way they actually accomplish state transitions. The connectionist systems created to date exhibit fragments of the appropriate transitional behavior, and that's a promising sign. We just don't know, yet, whether whole cognitive systems, exhibiting all the sorts of state transitions exhibited by cognizing agents, can be stitched together from such fabrics.
One of the virtues of vector-coding talk, then, is its neutrality; it avoids the spurious connotations of pictures or sentences. But that very neutrality might actually prevent one from thinking vividly enough to dream up good experiments that reveal something about the actual machinery determining the contents. Ramachandran has conducted a series of ingenious experiments designed to shed light on the question of how rich perceptual representations are, and the metaphor of pictorial filling in has apparently played a large role in guiding his imaginative transition from experiment to experiment (Ramachandran and Gregory, 1991, Ramachandran, 1992, in press). I have been sharply critical of reliance on this "filling in" metaphor (Dennett, 1991, 1992), but I must grant that any perspective on the issue that encourages dreaming these experiments up is valuable for just that reason, and should not be dismissed out of hand, even if in the end we have to fall back on some more neutral description of the phenomena.
One of the most dramatic of these experiments is Ramachandran and Gregory's "artificial scotoma" which the brain "fills in" with "twinkle". According to Ramachandran (1992), it can be reproduced at home, using an ordinary television set. (I must confess that my own efforts to achieve the effect at home have not been successful, but I do not doubt that it can be achieved under the right conditions.)
Choose an open channel so that the television produces 'snow,' a twinkling pattern of dots. Then stick a very tiny circular label in the middle of the screen. About eight centimenters from the label, tape on a square piece of gray paper whose sides are one centimeter and whose luminances roughly matches the gray in the snow. . . . If you gaze at the label very steadily for about 10 seconds, you will find that the square vanishes completely and gets 'replaced' be the twinkling dots. . . . . Recently we came up with an interesting variation of the original 'twinkle' experiment. When a volunteer indicated that the square had been filled in with twinkling dots, we instructed the computer to make the screen uniformly gray. To our surprise, the volunteers reported that they saw a square patch of twinkling dots in the region where the origianl gray square had been filled in. The saw the patch for as long as 10 seconds. (1992, p.90)In this new perceptual illusion, the illusory content is that there is twinkling in the square. But, one is tempted to ask, how is this content rendered? Is it a matter of the representation being composed of hundreds or thousands of individual illusory twinkles or is it a matter of there being, in effect, a label that just says "twinkling" attached to the representation of the square?
Can the brain represent twinkling, perceptually, without representing individual twinkles?This is a good mind-opening question, I think. That is, if you ask yourself this question, you are apt to discover something about how you have been tacitly understanding the issues--and the terms--all along. Real twinkling--twinkling in the world--is composed of lots of individual twinkles, of course, happening at particular times and places. That's what twinkling is. But not all representations of twinkling are composed of lots of representations of individual twinkles, happening at particular times and places. For instance, this essay frequently represents twinkling, but never by representing individual twinkles. We know that during the induction phase of this experiment, over a large portion of your retina, there are individual twinkles doing their individual work of getting the twinkle-representation machinery going, by stimulating particular groups of cells at particular times and places. What we don't yet know is whether, when neurally represented twinkling "fills in" the neurally represented square area--an area whose counterpart on the retina has no individual twinkles, of course--this represented twinkling consist of individual representations of twinkles. This is part of what one might want to know, when the question one asks is: How rich is the neural representation? It is an empirical question, and not at all an obvious one. It does not follow from the fact that we see the twinkling that the individual twinkles are represented. They may be, but this has yet to be determined. The fact that the twinkling is remarkably vivid, subjectively, also settles nothing. There are equally stunning illusory effects that are surely not rendered in individual details.
When I first saw Bellotto's landscape painting of Dresden at the North Carolina Museum of Art in Raleigh, I marveled at the gorgeously rendered details of all the various people walking in bright sunlight across the distant bridge, in their various costumes, with their differences in attitude and activity.

I remember having had a sense that the artist must have executed these delicate miniature figures with the aid of a magnifying glass. When I leaned close to the painting to examine the brushwork, I was astonished to find that all the little people were merely artfully positioned single blobs and daubs of paint--not a hand or foot or head or hat or shoulder to be discerned.

Nothing shaped remotely like a tiny person appears on the canvas, but there is no question that my brain represented those blobs as persons. Bellotto's deft brushwork "suggests" people crossing the bridge, and my brain certainly took the "suggestion" to heart. But what did its taking the suggestion amount to? We may want to say, metaphorically, that my brain "filled in" all the details, or we may want to say--more abstractly, but still metaphorically--that my brain completed the vector: a variety of different people in various costumes and attitudes. What I doubt very much, however, is that any particular neural representations of hands or feet or hats or shoulders were created by my brain. (This, too, is an empirical question, of course, but I'll eat my hat if I'm wrong about this one!)
How can we tell, then, how rich the content of the neural representation actually is? As Ramachandran says, by doing more experiments. Consider for instance another of his embellishments on the artificial scotoma theme, in which the twinkling background is colored pink, and there is a "conveyor belt" of spots coherently moving from left to right within the gray square region.(Ramachandran, in press). As before, the square fades, replaced by pink, but the conveyor belt continues for awhile, before its coherent motion is replaced by the random jiggling of the rest of the background. Ramachandran concludes, correctly, that there must be two separate "fill in" events occurring in the brain; one for the background color, one for the motion. But he goes on to draw a second conclusion that doesn't follow:
The visual system must be actually seeing pink--i.e., creating a visual representation of pink in the region of the scotoma, for if that were not true why would they actually see the spots moving against a pink background? If no actual filling in were taking place they would simply have been unable to report what was immediately around the moving spots. (in press, ms p.14)Of course in some sense "the visual system must be actually seeing pink"--that is, the subject is actually seeing pink that isn't there. No doubt about it! But this does not mean the pink is represented by actually filling in between the moving spots on the conveyor belt--and Ramachandran has yet another experiment that shows this: when a "thin black ring" was suddenly introduced in the center of the square, the background color, yellow, "filled the interior of the ring as well; its spread was not 'blocked' by the ring." As he says,
This observation is especially interesting since it implies that the phrase 'filling in' is merely a metaphor. If there had been an actual neural process that even remotely resembled 'filling in' then one would have expected its progress to be blocked by the black ring but no such effect occurred. Therefore we would be better off saying that the visual system 'assigns' the same color as the surround to the faded region . . . (in press, ms page 16)In yet another experiment, Ramachandran had subjects look at a tfixation point on a page of text which had a blank area off to the side. Subjects duly "filled in" the gap with text. But of course the words were not readable, the letters were not identifiable. As Ramachandran says: "It was as though what was filled in was the 'texture' of the letters rather than the letters themselves." (in press, p.15) No rendering of individual letters, in other words, but rather a representation to the effect that there was no gap in the text, but just more of the same--more 12-point Times Roman, or whatever. The effect is, of course, perceptual, but that does not mean it is not conceptual, not propositional. The content is actually less rich than it would have to be, if the gap were filled with particular letters spelling out particular words (or nonwords).
Let's now return to the opening question: what is the product of perception? This question may have seemed at first like a good question to ask, but it gets one off on the wrong foot because it presupposes that perceptual processes have a single kind of product. To presuppose this, however, is already to commit oneself to the Cartesian Theater. There are in fact many different way of turning the corner, or responding to the given, and only a few of them are "pictorial" (or for that matter "sentential") in any sense at all. For instance, when something looms swiftly in the visual field, one tends to duck. Ducking is one sort of taking. It itself is not remotely pictorial or propositional; the behavior is not a speech act; it does not express a proposition. And there is no reason on earth to posit an intermediary state that "represents" in some "code" or "system of representation".
Suppose a picture of a cow is very briefly flashed in your visual field, and then masked. You might not be able to report it or draw it, but it might have the effect of making you more likely to say the word "milk" if asked to name a beverage. This is another sort of corner turning; it is presumably accomplished by activating or sensitizing a particular semantic domain centered around cows, so your visual system must have done its interpretive work--must have completed the cow vector--but its only "product" on this occasion may be just to turn on the cow-neighboring portion of your semantic network.
The magician moves his hand just so, misdirecting you. We know he succeeded, because you exhibit astonishment when he turns over the cup and the ball has vanished. What product did he produce by this manipulation of your visual system? Astonishment now, but that, like ducking, is not a speech act. The astonishment is caused by failed expectation; you had expected the ball to be under the cup. Now what sort of a "product" is this unarticulated expectation? Is it a sentence of mentalese, "The ball is under the cup" swiftly written in your belief-box, or is it a pictorial representation of the ball under the cup? It's something else, propositional only in the bland sense that it is content-specific; it is about the ball being under the cup, which is not the same thing as being about the cup being on the table or being about the magician having moved his hands away from the cup. Those are different products of visual perception, vectors into different regions of your content hyperspace.
This state that you have been put into not only grounds your astonishment if the magician now turns over the cup, but also influences how you will perceive the next move the magician makes if he doesn't turn over the cup. That is, this "product" of perception can immediately go on to influence the processes producing the next products of perception, and on and on. Ramachandran illustrates this point with an experiment in which a field of yellow rings is shown to subjects in such a way that one of the rings has its inner boundary obscured by the blind spot.

What will their brains do? "Fill in" with yet another ring, just like all the other rings, or "fill in" the center of the obscured ring with yellow, turning it into a yellow disk? The latter, it turns out; the solid yellow disk "pops out" as the exception in the field of yellow rings. But even this is not a demonstration of actual filling in; in this case, the brain has evidence that there is a yellow region with a circular perimeter, and it has no local evidence about whether or not the whole region is yellow. Not having any contrary evidence, it draws the inference that it must be "more of the same"--more yellow. This is a fine example of a micro-taking, for this "conclusion" amounts to the creation of the content yellow disk, which in turn becomes a premise of sorts: the odd-one-out in a field represented as consisting of yellow rings, which then triggers "pop out". It might have turned out otherwise; the micro-taking process first invoked for the blind spot region might have had access to the global information about the multitude of rings, and treated this global content as evidence for a different inference: considered globally, "more of the same" is more rings. In that case there would have been no pop-out, and the field would have been seen, veridically, in fact, as a uniform field of rings. So the experiment very definitely shows us something about the order and access relations between a variety of micro-takings, but in neither case does the brain have to provide something in order to arrive at its initial judgment.
The creation of conscious experience is not a batch process but a continuous process. There is not one corner that is turned, once, but many. The order in which these determinations occur determines the order in which they can have effects (no backwards causation allowed!), but is strictly independent of the order represented in the contents thus determined. The micro-takings have to interact. A micro-taking, as a sort of judgment or decision, can't just be inscribed in the brain in isolation; it has to have its consequences--for guiding action and modulating further micro-judgments made "in its light." This interaction of micro-takings, however it is accomplished in particular cases, has the effect that a modicum of coherence is maintained, with discrepant elements dropping out of contention, and all without the assistance of a Master Judge. Since there is no Master Judge, there is no further process of being-appreciated-in-consciousness, so the question of exactly when a particular element was consciously (as opposed to unconsciously) taken admits no non-arbitrary answer. And since there is no privileged moment at which to measure richness of content, and since the richness of content of micro-takings waxes and wanes, the idea that we can identify perceptual--as opposed to conceptual--states by an evaluation of their contents turns out to be an illusion.
Dennett, D. C., 1978, Brainstorms, Cambridge, MA: MIT Press.
Dennett, D. C., 1991, Consciousness Explained, Boston: Little, Brown.
Dennett, 1992, "Filling in versus finding out: A ubiquitous confusion in cognitive science," in H. den Broek and D. Knill, eds., Cognition: Conceptual and Methodological Issues, American Psychological Association.
Dennett, D. C., and Kinsbourne, M., 1992, "Time and the Observer: the Where and When of Consciousness in the Brain," Behavioral and Brain Sciences, xxx,xxx.
Kinsbourne, M., 1988, "Integrated Field Theory of Consciousness," in A. J. Marcel and E. Bisiach, eds., Consciousness in Contemporary Science, Oxford: Oxford Univ. Press.
Ramachandran, V. S., 1992, "Blind Spots," Scientific American, 266, May 1992, pp86-91.
Ramachandran, V. S., and Gregory, R. L., 1991, "Perceptual Filling In of Artificially Induced Scotomas in Human Vision," Nasture, 350, No. 6320, pp. 699-702.
Ramachandran, V. S., in press, "Filling In Gaps in Perception," in Current Directions in Psychological Science.*
Stalnaker, R., 1984, Inquiry, Cambridge, MA: MIT Press.
*The quotes from this are taken from the typescript; final page numbers, and confirmation of the wording, must await final publication of the piece.
1. This is what I called the -manifold in "Two Approaches to Mental Images," in Dennett, 1978.